June 10, 2023
The next step is to create the first UI page to display the list of existing links. Even though I followed SST’s docs for creating a NextJS project, linking NextJS, SST, and MUI together was fraught.
Bring NextJS and MUI Online
To get it all in sync, I ended up cloning the SST NextJS quickstart example and copying over files until I was able to see Next’s Hello World UI:

Then, I did the same with MUI’s NextJS (Typescript) example until I could that Hello World UI:
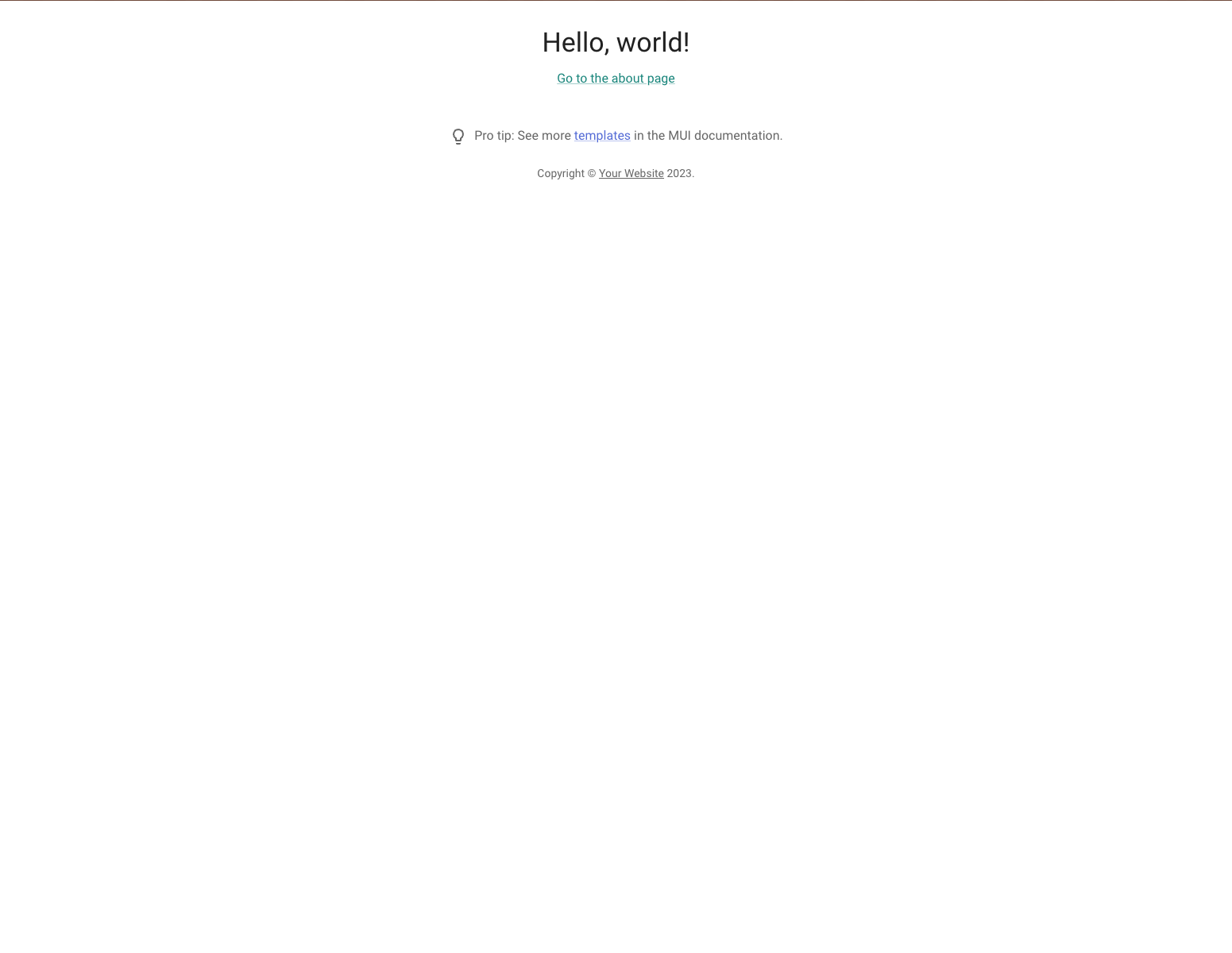
You can view these changes in the Next UI works in dev and Add MUI PRs.
I’m eternally grateful to the devs that have written countless examples for the MUI and SST projects; without those examples, I don’t think I would’ve been able to move forward on this project with these tools.
Poll the API for Links
Finally, let’s connect the UI to the API data! First, we’ll expose the api construct in stacks/API.ts so that we can bind it to the UI:
// ...
stack.addOutputs({
ApiEndpoint: api.url,
});
return { api };
}
Then bind the api to the site under stacks/Site.ts:
export function Site({ stack }: StackContext) {
const { api } = use(API);
const site = new NextjsSite(stack, "site", {
bind: [api],
});
On the index page (src/pages/index.tsx), we can create a Link type and use getServerSideProps to fetch data from the API:
type Link = {
shortPath: string;
url: string;
uid: string;
};
export const getServerSideProps: GetServerSideProps<{
links: Link[];
}> = async (context) => {
const endpoint = `${Api.api.url}/links`;
const res = await fetch(endpoint);
const data = await res.json();
return { props: data.body };
};
There’s a possible breakdown between the UI and API here if the Link type skews from what the API returns, so I created an issue to revisit this in the future. In that same file, we’ll add some basic p tags for each link we receive:
export default function Home({ links }: { links: Link[] }) {
return (
<Container maxWidth="lg">
{/* ... */}
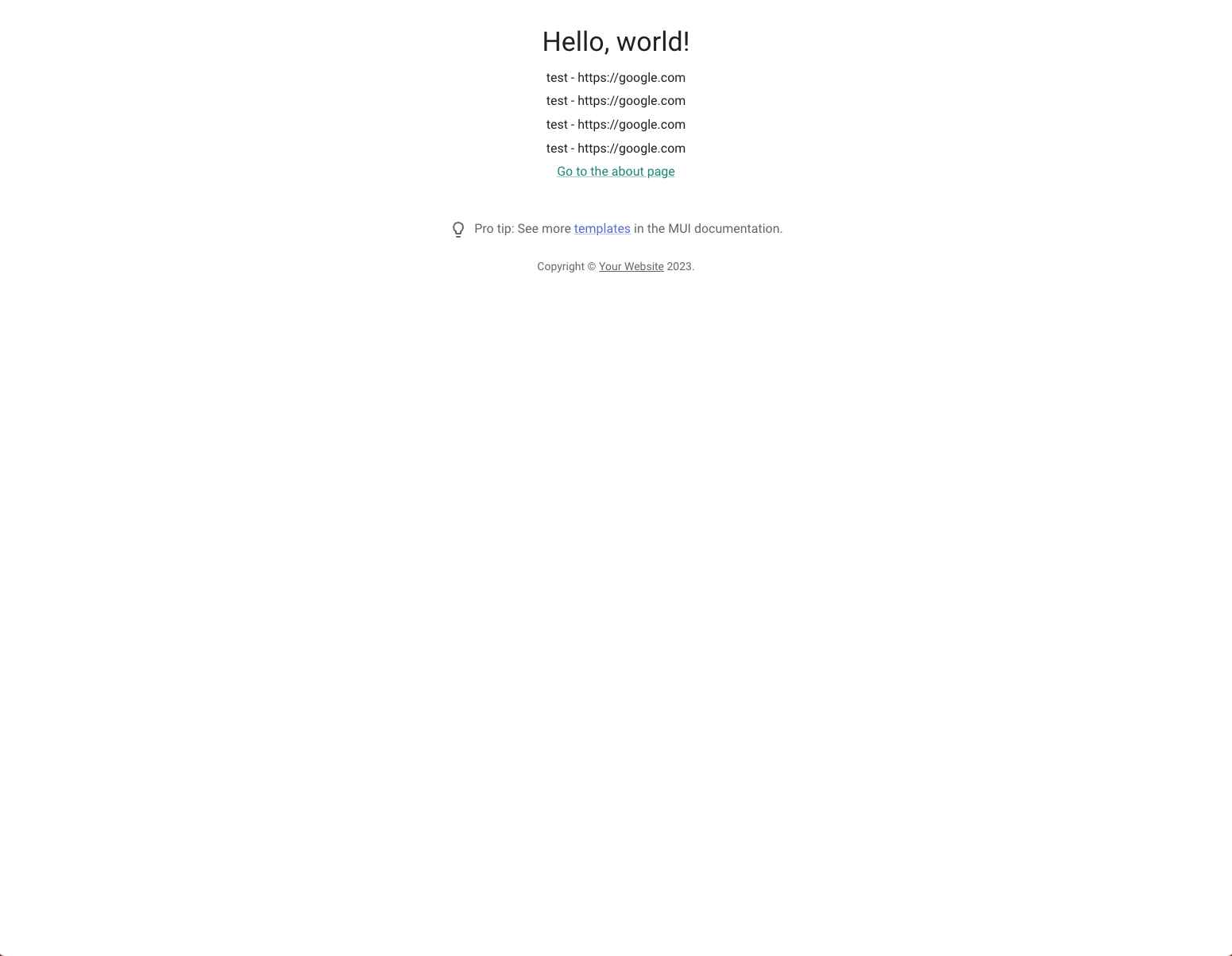
{links &&
links.map((link) => (
<Typography
variant="body1"
component="p"
gutterBottom
key={link.uid}
>
{link.shortPath} - {link.url}
</Typography>
))}
One last thing: NextJS requires an experimental flag in next.config.js to make this work. I think it’s to allow async calls inside getServerProps:
const nextConfig = {
reactStrictMode: true,
webpack(config) {
config.experiments = { ...config.experiments, topLevelAwait: true };
return config;
},
};
And there we go, links! You can view this code on the Index shows list of links PR.
June 9, 2023
Today we’ll round out the first version of the API by:
- Adding create and update timestamps to
Link entities
- Un-hardcoding the link create function
- Adding a way to edit links
- Adding a way to redirect to a URL from a short path
Add Timestamps to Links
ElectroDB lets us add createdAt and updatedAt timestamps very easily, thanks to the ability to set readOnly: true and/or a watch property to modify attributes when the entity is already being edited. We’ll lift straight from their example by editing the LinkEntity in packages/core/src/link.ts:
export const LinkEntity = new Entity(
{
model: {
entity: "links",
version: "1",
service: "cowlinks",
},
attributes: {
// ...
createdAt: {
type: "number",
readOnly: true,
set: () => Date.now(),
},
updatedAt: {
type: "number",
readOnly: true,
watch: "*",
set: () => Date.now(),
},
Now, ElectroDB will automatically set createdAt whenever a new entity is created (and only the model can set this, not the user), and it will update updatedAt whenever any other property on the entity changes as well.
Un-hardcode the link create endpoint
Earlier, we hardcoded each link that was created to redirect to Google. Let’s update packages/functions/src/link/create.ts to use the url and shortPath parameters from the POST body:
export const handler = ApiHandler(async (_evt) => {
const { url, shortPath } = useJsonBody();
const newLink = await Link.create(shortPath, url);
return {
body: JSON.stringify({
link: newLink,
},
}),
};
});
Here, useBody is an SST builtin from the api client.
Add link PATCH and list
Originally, I was going to use the verb PUT instead of PATCH to edit links; however, ElectroDB’s put makes you provide all required attributes, and I prefer to only pass in the properties I wish to change. (Or at least, I like having the option to only provide the changed values.)
So I went with patch instead, especially since it ensures you’re not creating a new link accidentally:
In DynamoDB, update operations by default will create an item if record being updated does not exist. Alternatively, the patch method will utilize the attribute_exists() parameter dynamically to ensure records are only “patched” and not created when updating items in your table.
Adding the patch and list API endpoints is pretty straightforward. We’ll update stacks/API.ts to add two new functions:
const api = new Api(stack, "api", {
// ...
routes: {
// ...
"PATCH /link/{uid}": {
function: {
functionName: nameFor("LinkPatch"),
handler: "packages/functions/src/link/patch.handler",
},
},
"GET /links": {
function: {
functionName: nameFor("LinkList"),
handler: "packages/functions/src/link/list.handler",
},
},
Expose methods in packages/core/src/link.ts to patch and list LinkEntitys:
export async function getByShortPath(shortPath: string) {
const result = await LinkEntity.query.byShortPath({ shortPath }).go();
return result.data;
}
type PatchAttributes = UpdateEntityItem<typeof LinkEntity>;
export async function patch(uid: string, newAttributes: PatchAttributes) {
const result = await LinkEntity.patch({ uid }).set(newAttributes).go({
response: "all_new",
});
console.log({ result });
return result.data;
}
export async function list() {
const result = await LinkEntity.query.byUid({}).go();
return result.data;
}
We use response: "all_new" so that Dynamo returns the whole updated object in the response instead of an empty object. In a heavy-scale production system, I’d more strongly consider using the default response to use eventual consistency over strong consistency. However, I expect to save a lot more debugging pain by grabbing the entire object in the short term.
I found the UpdateEntityItem party trick from ElectroDB’s Typescript guide. It has a lot of nice helpers for the static types, although I had to hunt around for a while to find it, and it was unclear which type I should use for .patch() without some experimentation.
Write the patch handler at packages/functions/src/link/patch.ts:
export const handler = ApiHandler(async (_evt) => {
const linkUid = usePathParam("uid");
const newAttributes = useJsonBody();
if (!linkUid) {
return {
statusCode: 400,
body: "link uid is required",
};
}
const foundLink = await Link.get(linkUid);
console.log({ foundLink });
if (!foundLink) {
return {
statusCode: 404,
body: "not found",
};
}
const updatedLink = await Link.patch(foundLink.uid, newAttributes);
console.log({ updatedLink });
return {
statusCode: 200,
body: JSON.stringify({
link: updatedLink,
}),
};
});
And the list handler at packages/functions/src/link/list.ts:
export const handler = ApiHandler(async (_evt) => {
const result = await Link.list();
return {
body: {
links: result,
},
};
});
The Redirect Endpoint
Finally, the last and most important piece of the URL shortener: the redirect. I decided to use /s to designate shortened URLs (s for shorten), so API_URL/s/foo will look up a LinkEntity with a shortPath of foo and redirect to the entity’s url.
Let’s fix a bug in the LinkEntity under packages/core/src/link.ts so that we can find links by their shortPath:
export const LinkEntity = new Entity(
{
// ...
indexes: {
// ...
byShortPath: {
index: "gsi1",
Then we’ll add a new route in stacks/API.ts:
"GET /s/{shortPath}": {
function: {
functionName: nameFor("Redirect"),
handler: "packages/functions/src/redirect.handler",
},
},
And the corresponding handler in packages/functions/src/redirect.ts:
export const handler = ApiHandler(async (_evt) => {
const shortPath = usePathParam("shortPath");
if (!shortPath) {
return {
statusCode: 400,
body: "shortPath is required",
};
}
const foundLinks = await Link.getByShortPath(shortPath);
console.log({ foundLinks });
if (foundLinks.length === 0) {
return {
statusCode: 404,
body: "not found",
};
}
return {
statusCode: 301,
headers: {
Location: foundLinks[0].url,
},
};
});
And there we go! A finished v0 API. You can view this code in this git compare.
June 8, 2023
Let’s add an endpoint to get a list of all links that we’ve created. Start with adding a list function to packages/core/src/link.ts:
export async function list() {
const result = await LinkEntity.query.byUid({}).go();
return result.data;
}
Add the LinkList lambda function to the API stack in stacks/API.ts as well:
const api = new Api(stack, "api", {
routes: {
"GET /links": {
function: {
functionName: nameFor("LinkList"),
handler: "packages/functions/src/link/list.handler",
},
// ...
}
}
And there we go! You can view this code in the Add link list commit.