How to Fix Liquid Syntax Errors in React Code Snippets
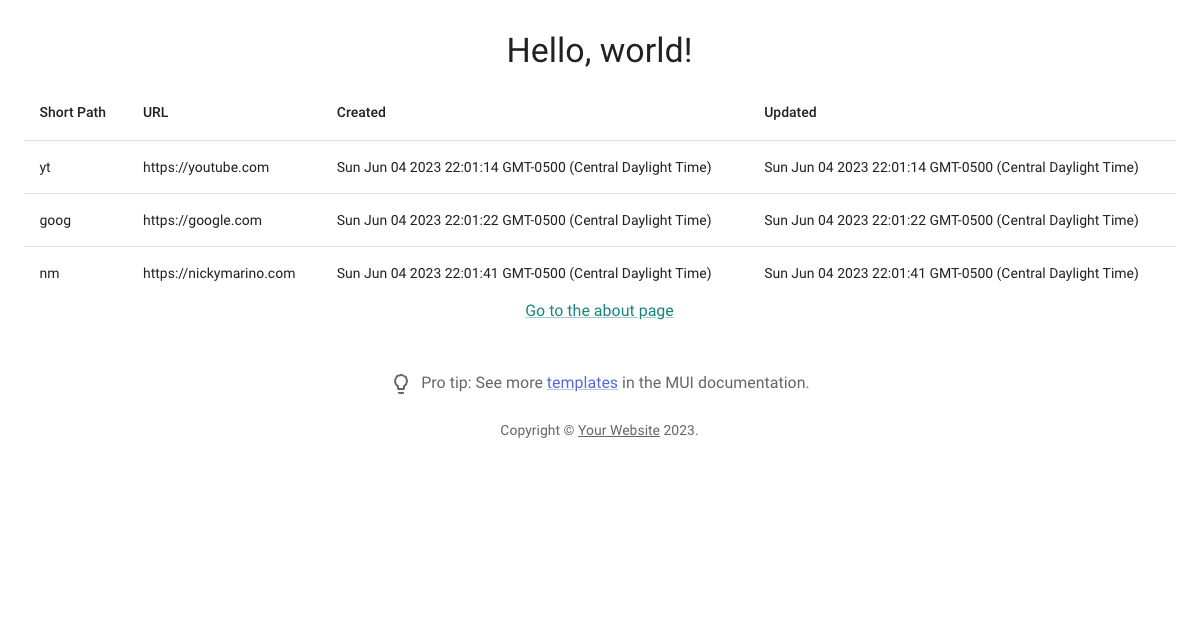
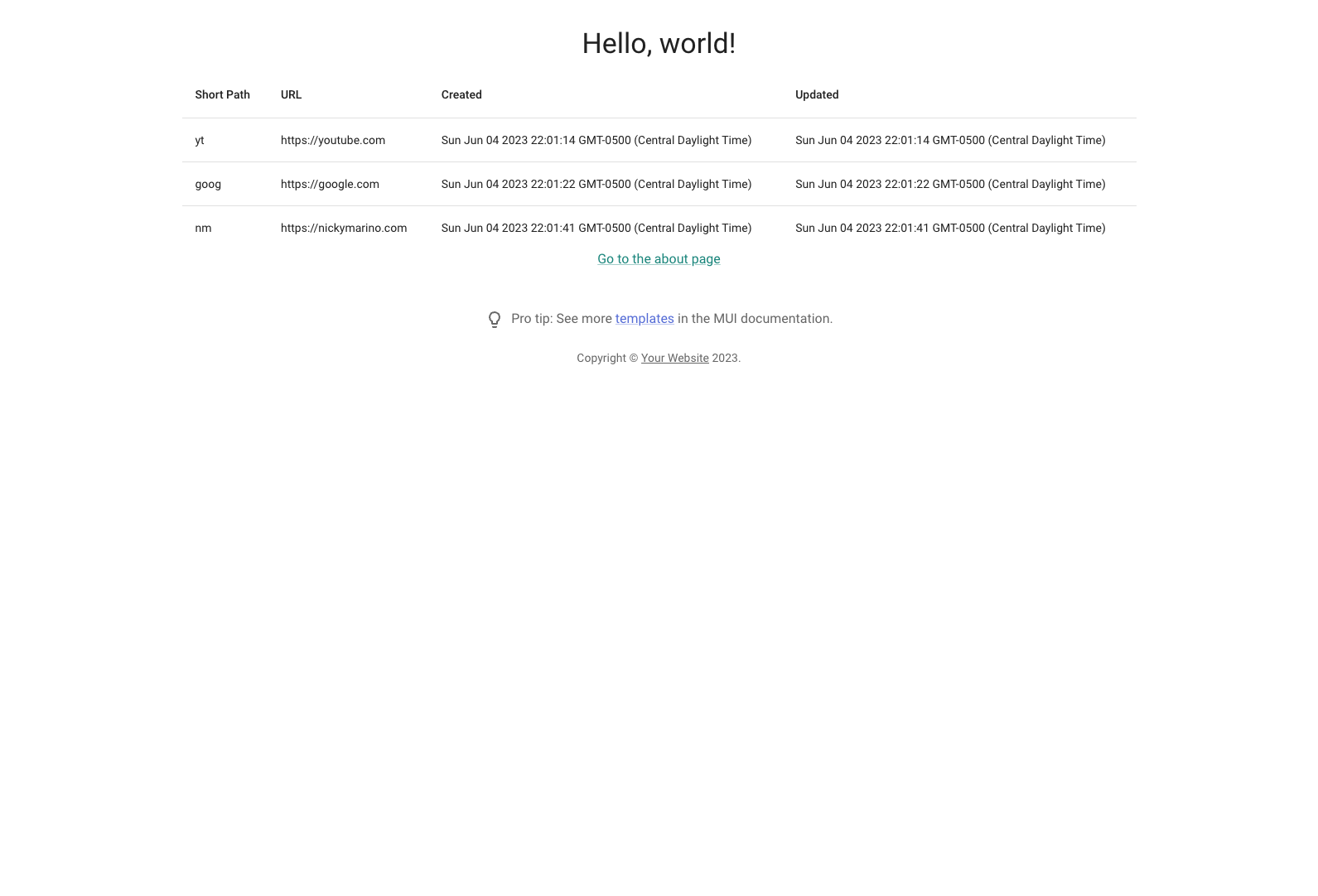
June 13, 2023While publishing my series of dev diaries for my URL shortener project, I encountered some strange errors from Jekyll. Below is example code to create a table using MUI in React:
return (
<Table sx={{ minWidth: 650 }} aria-label="simple table">
<TableHead>
<TableRow>
<TableCell>Short Path</TableCell>
<TableCell>URL</TableCell>
<TableCell>Created</TableCell>
<TableCell>Updated</TableCell>
</TableRow>
</TableHead>
<TableBody>
{links.map((row) => (
<TableRow
key={row.uid}
sx={{ "&:last-child td, &:last-child th": { border: 0 } }}
>
<TableCell component="th" scope="row">
{row.shortPath}
</TableCell>
<TableCell>{row.url}</TableCell>
<TableCell>{toTimestamp(row.createdAt)}</TableCell>
<TableCell>{toTimestamp(row.updatedAt)}</TableCell>
</TableRow>
))}
</TableBody>
</Table>
);
}
When I save this codeblock to a markdown file, I get a strange syntax error from liquid out of nowhere:
Regenerating: 2 file(s) changed at 2023-06-05 19:31:13
_posts/2023-06-13-yyyy.md
.history/_posts/2023-06-13-yyyy_20230605193112.md
Liquid Exception: Liquid syntax error (line 70): Variable '{{ "&:last-child td, &:last-child th": { border: 0 }' was not properly terminated with regexp: /\}\}/ in /Users/nickymarino/Dropbox/Mac (3)/Documents/Developer/nickymarino.github.io/_posts/2023-06-13-yyyy.md
Error: Liquid syntax error (line 70): Variable '{{ "&:last-child td, &:last-child th": { border: 0 }' was not properly terminated with regexp: /\}\}/
Error: Run jekyll build --trace for more information.
This was really strange to me. At first I couldn’t figure out what liquid even was–I had forgotten it’s a tool Jekyll uses to pre-process markdown files–and I wasn’t sure why liquid was looking inside the codeblock.
Thanks to chuckhoupt’s comment on the Jekyll help forum though, I learned I can wrap my code in a raw tag to prevent processing:
<!--
{% raw %}
Disable liquid parsing on this codeblock to prevent errors reading '{{'
See: https://talk.jekyllrb.com/t/code-block-is-improperly-handled-and-generates-liquid-syntax-error/7599/2
-->
```ts
return (
<Table sx={{ minWidth: 650 }} aria-label="simple table">
<TableHead>
<TableRow>
<TableCell>Short Path</TableCell>
<TableCell>URL</TableCell>
<TableCell>Created</TableCell>
<TableCell>Updated</TableCell>
</TableRow>
</TableHead>
<TableBody>
{links.map((row) => (
<TableRow
key={row.uid}
sx={{ "&:last-child td, &:last-child th": { border: 0 } }}
>
<TableCell component="th" scope="row">
{row.shortPath}
</TableCell>
<TableCell>{row.url}</TableCell>
<TableCell>{toTimestamp(row.createdAt)}</TableCell>
<TableCell>{toTimestamp(row.updatedAt)}</TableCell>
</TableRow>
))}
</TableBody>
</Table>
);
}
```
<!-- {% endraw %} -->
While writing this post, I also discovered this trick by Josh to wrap the double quotes in a variable:
{{
The downside is that it leads to some strange looking code. For example, to escape the above raw and endraw tags, I used:
<!--
{% raw %}
...
-->
<!-- {% endraw %} -->
Outside of code snippets, you can use the HTML entities as well: { and }. And to write this post, I had to use this trick by Waylan to use more backticks to mark the start and end of a snippet:
````text
<!-- ... -->
```ts
return ( ... )
```
<!-- ... -->
````